背景
集群背景:48Core,256GMem,24台节点的集群。每台节点给Nodemanager分配了128G。
问题
结果一次大型任务运行时,150亿的表和400亿的表做join时,每台节点的内存居然100%打满了。我这里的100%是整个节点的100%,而我们给所有大数据的组件内存才不到200G。
当时是懵的。
后面我们监控任务运行时,发现nodemanager的内存居然达到了180G左右,远远超出了我们设置的128G。后面查阅资料,诊断出问题,应该是Nodemanager中运行的Spark使用了大量的堆外内存,不在堆内,不可控。那么我们直接开启了 yarn.nodemanager.pmem-check-enabled,该参数可以很好的限制nodemanager整体的内存,包括堆外。
但是设置完之后,发现集群内存资源是正常了,但是任务却报错了,报错内容如下
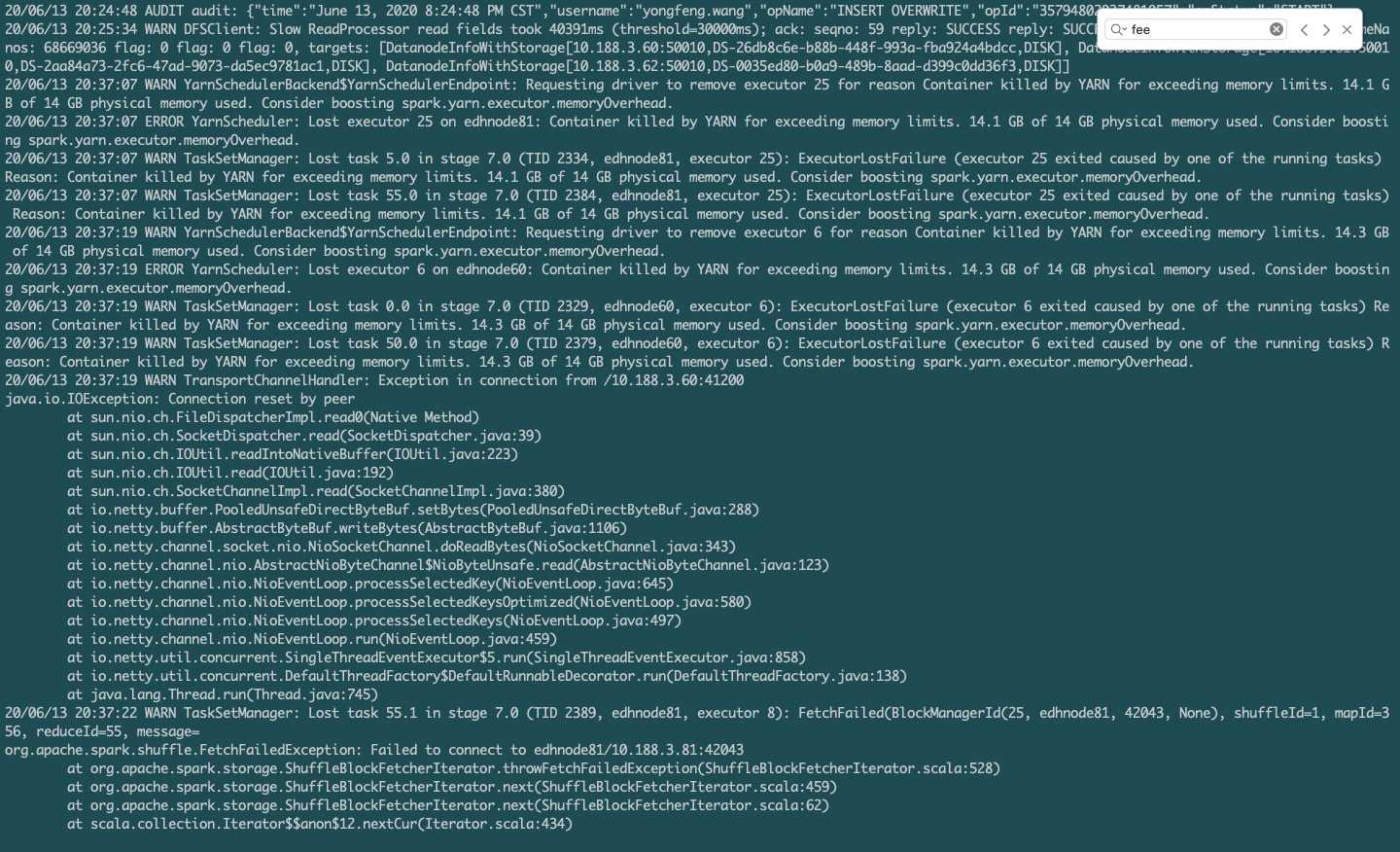
继续查阅资料,发现是由于我们开启了 yarn.nodemanager.pmem-check-enabled 导致的,那么不开启又会内存不可控,而不开启任务又会失败。
继续查阅资料,发现可以通过配置任务的 --conf "spark.yarn.executor.memoryOverhead=4G" 该属性可以解决。
其实我们的任务的 execute-memory 配置的是12G,为啥为说超过14G勒?
原来Yarn的堆外内存默认配置为: max( executorMemory * 0.10,384M),也就是说12G的10%,为1.2。
然后这里的1.2G并不是可分配的最后实际值。
yarn 中有个参数为 yarn.scheduler.increment-allocation-mb
该参数就是说,你分配的最小单位是多少,这里默认是1G,也就是说你分配10M,也要1G,分配1.1G,就要2G,最小取值单位为1G。
那么我们这里的 max( executorMemory * 0.10,384M) 结果就是2G了。
还没完…
然后具体的 memoryOverhead 公式为, execute-memory + max( executorMemory * 0.10,384M)。 即: 12G + 2G 就是4G。
还没完…
这里的 max( executorMemory * 0.10,384M) 并不一定是最后结果,他有个判断,如果你设置了 spark.yarn.executor.memoryOverhead 属性,就直接去该属性的值了。
参考博客
我上面说的,不一定能看懂,可以借鉴一篇博客中的原话。
Container killed by YARN for exceeding memory limits
其中,MEMORY_OVERHEAD_FACTOR默认为0.1,executorMemory为设置的executor-memory, MEMORY_OVERHEAD_MIN默认为384m。参数MEMORY_OVERHEAD_FACTOR和MEMORY_OVERHEAD_MIN一般不能直接修改,是Spark代码中直接写死的
executor-memory计算
val executorMem = args.executorMemory + executorMemoryOverhead
1) 如果没有设置spark.yarn.executor.memoryOverhead,
executorMem= X+max(X*0.1,384)
如果设置了spark.yarn.executor.memoryOverhead(整数,单位是M)
executorMem=X +spark.yarn.executor.memoryOverhead
设置executorMem需要满足的条件:
xecutorMem< yarn.scheduler.maximum-allocation-mb
原创文章,转载请注明: 转载自LoserZhao – 诗和远方[ http://www.loserzhao.com/ ]
本文链接地址: http://www.loserzhao.com/bigdata/yarn-memory-outof-yarn-nodemanager-resource-memory-mb.html
文章的脚注信息由WordPress的wp-posturl插件自动生成
1 条评论。