环境
Spark 1.6.3
SparkContext的初始化变量
从SparkContext从上一直阅读初始化成员变量,发现在这一段,开始给 SchedulerBackend、TaskScheduler、 DAGScheduler进行初始化。
而初始化方式是
|
1 2 3 4 |
SparkContext.createTaskScheduler(this,master) // this:SparkContext // master:是自己代码中调用SparkConf.setMaster()方法传递的 |
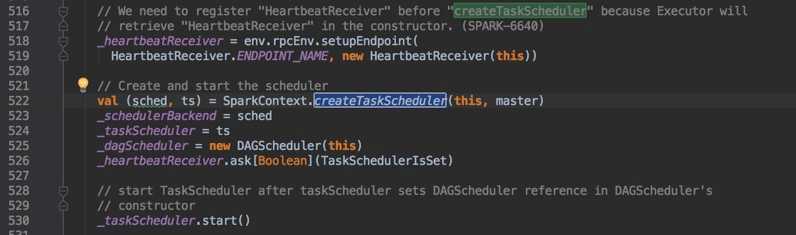
createTaskScheduler 只是根据Spark运行模式而创建对应的TaskScheduler和SchedulerBackend
local模式

Standalone模式
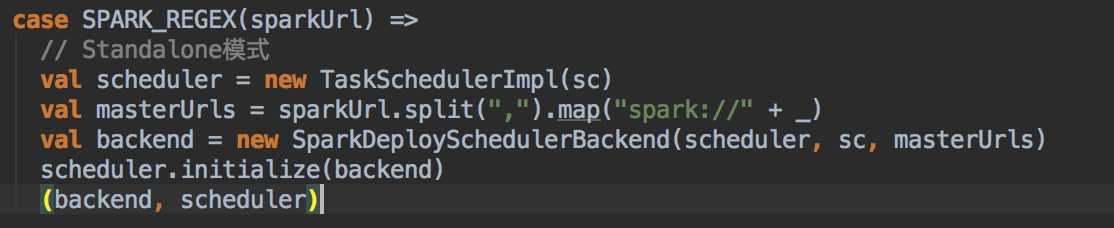
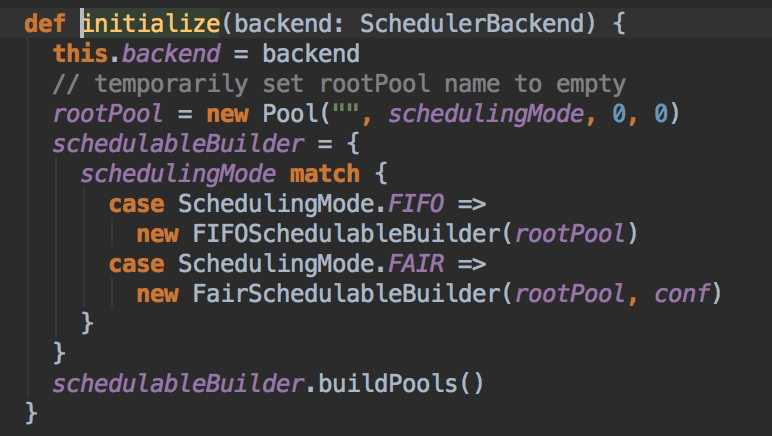
咱们这里主要以Standalone模式为主,scheduler.initialize(backend)里面只是创建调度池。这里是支持两种调度方式,FAIR和FIFO。默认的调度池 Pool => FIFO。
继续回到SparkContext,在 528 行发现启动了 taskScheduler 的启动。
|
1 2 3 4 |
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's // constructor _taskScheduler.start() |
taskScheduler 的实现方法是 TaskSchedulerImpl。
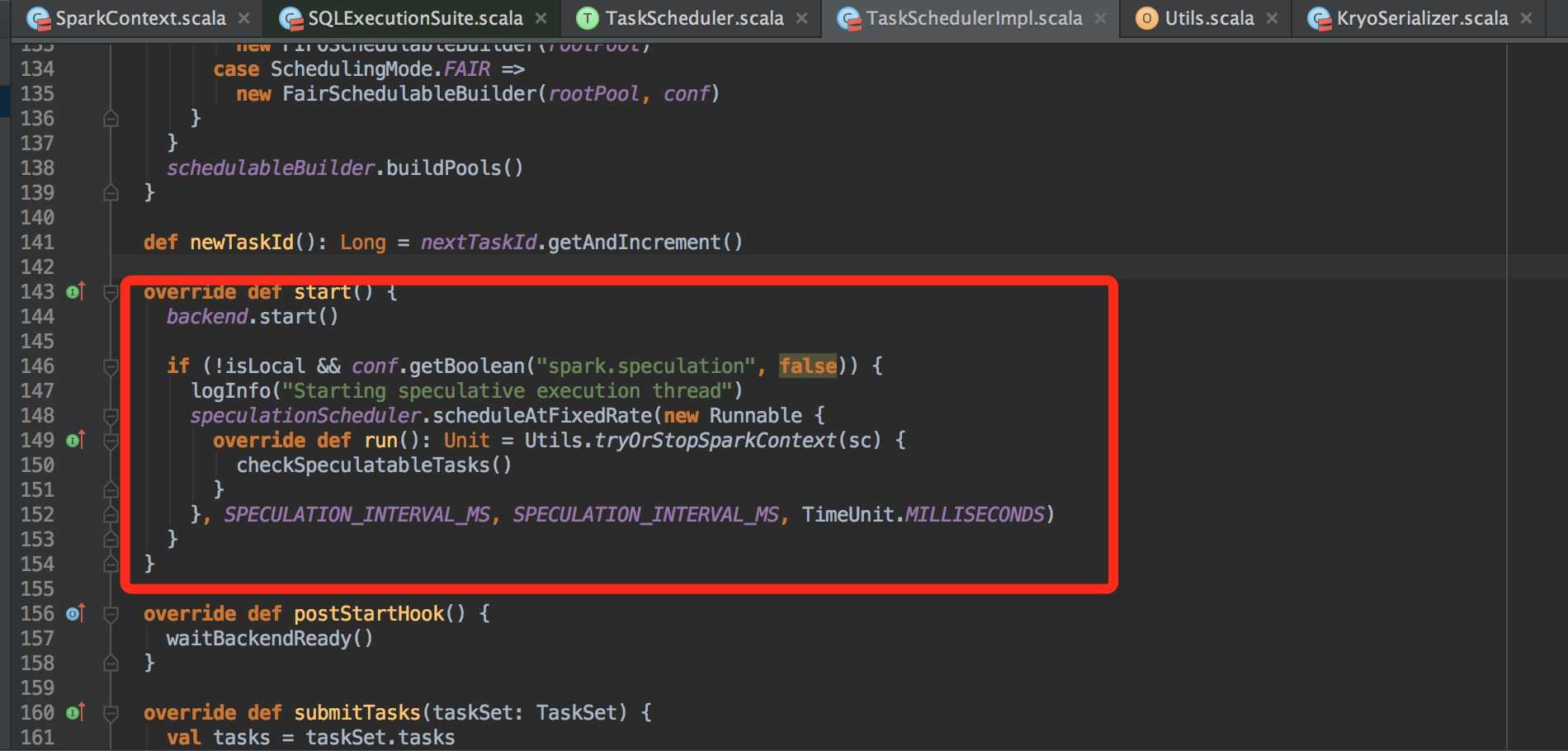
这里的 backend 是 SchedulerBackend,那么继续看对应的Start方法
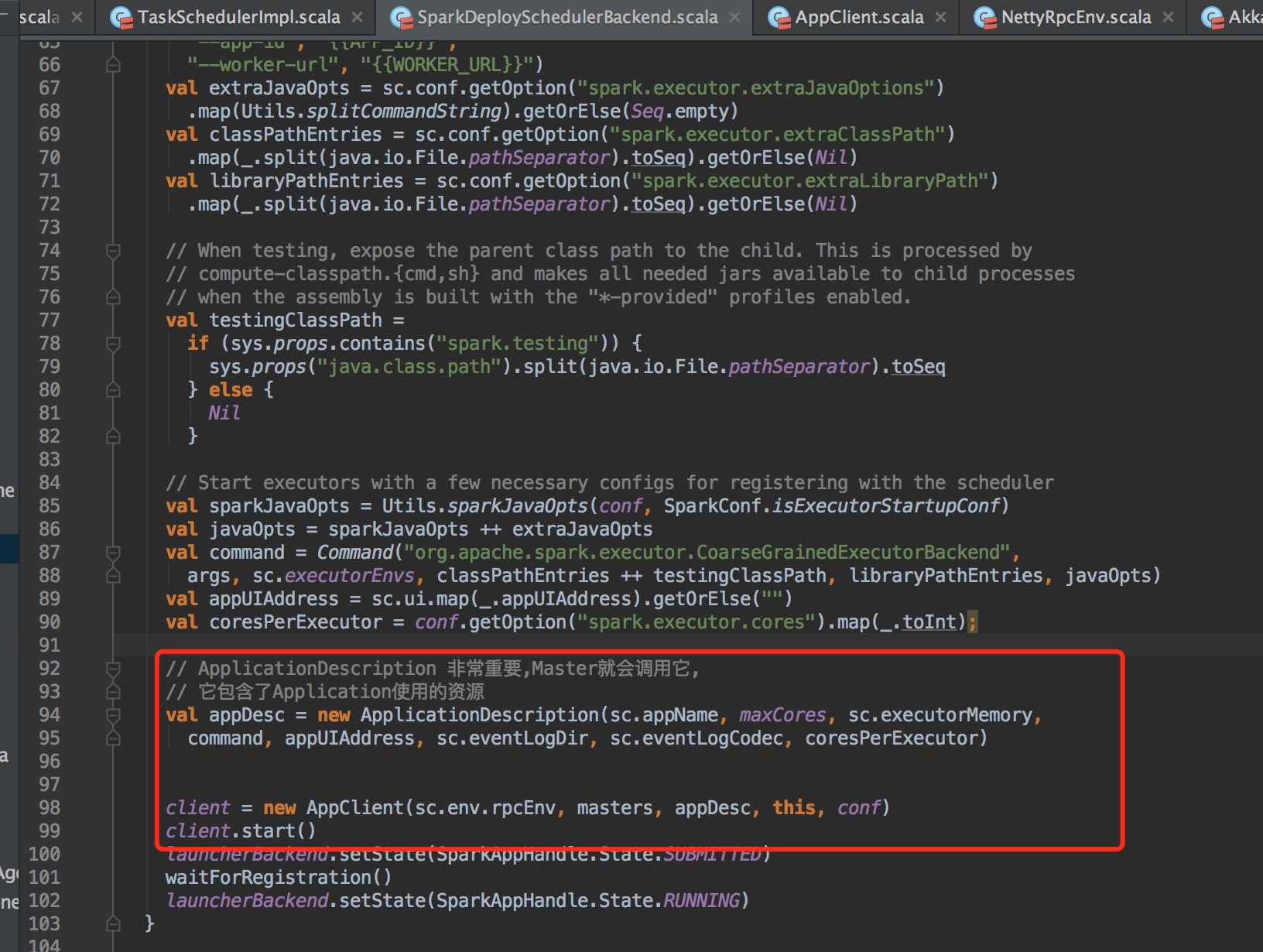
ApplicationDescription 只是封装了使用资源,例如:Core、Memory。
AppClient 主要是用来 Application 和 Spark 集群通信的类。继续研究其Start方法。

继续跟踪ClientEndpoint,发现该类只是AppClient的内部类,然而 extends ThreadSafeRpcEndpoint。 对于 ThreadSafeRpcEndpoint 的生命周期,咱们主要看Start方法,然后看其 registerWithMaster[1] 方法。

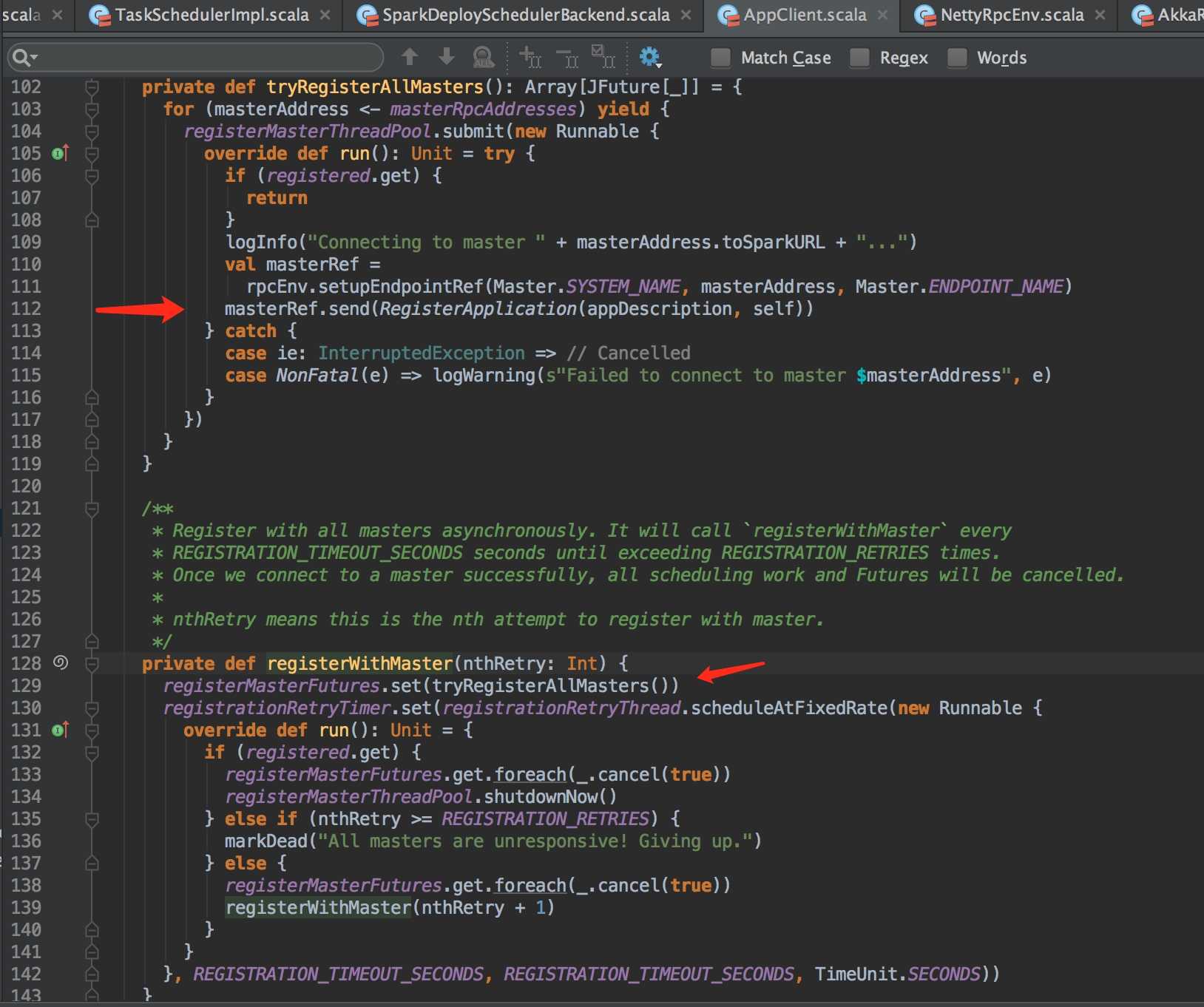
最后就是通过 RpcEndpoint 的实现类》Netty/Akka 来实现通信注册Application了。
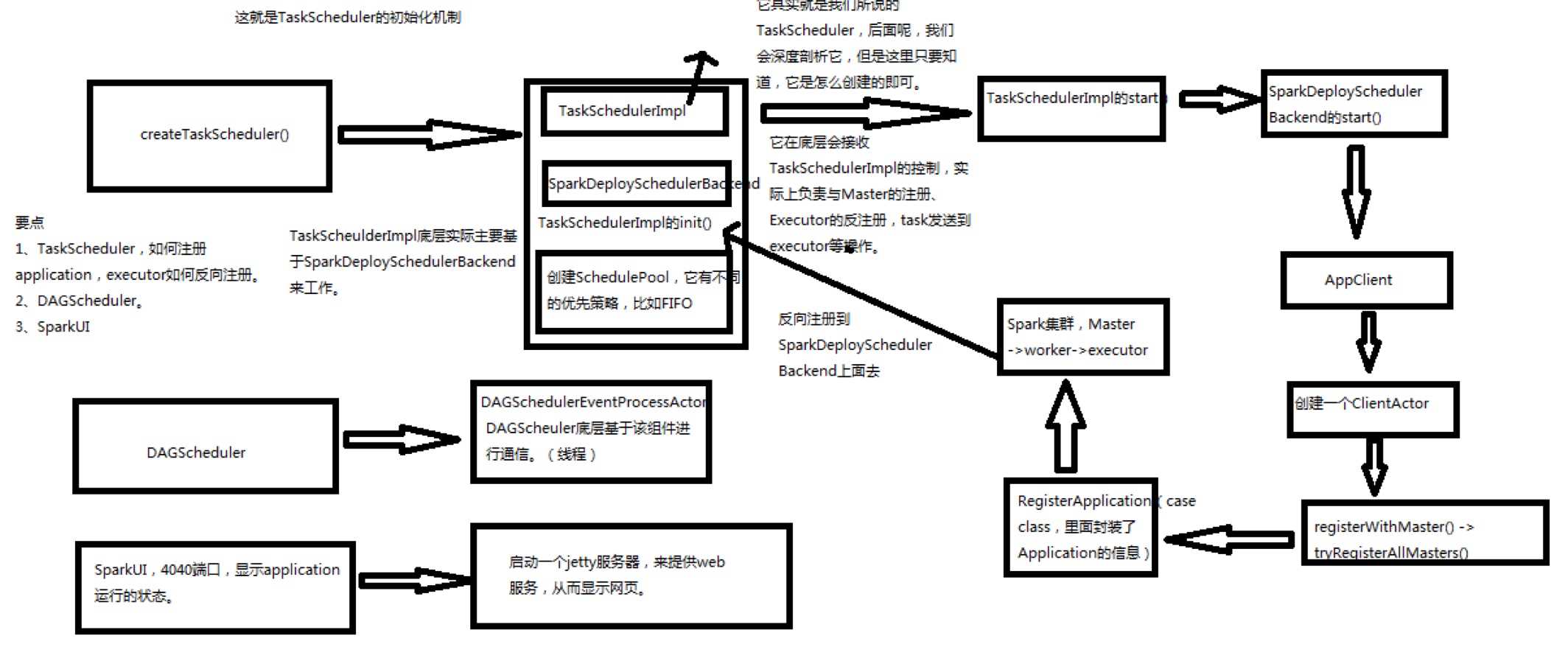
最后附上一张Spark源码分析图
原创文章,转载请注明: 转载自LoserZhao – 诗和远方[ http://www.loserzhao.com/ ]
本文链接地址: http://www.loserzhao.com/bigdata/sparkcontext-taskscheduler-source-analysis.html
文章的脚注信息由WordPress的wp-posturl插件自动生成
0 条评论。