描述
为了运行一个应用程序,Spark首先根据应用程序资源需求构建一个运行时环境,这是通过与资源管理器交互来完成的。通常而言,存在两种运行时环境构建方式:粗粒度和细粒度。
粗粒度
应用程序被提交到集群之后,它在正式运行任务之前,将根据应用程序资源需求一次性将这些资源凑齐,之后使用这些资源运行任务,整个运行过程中不再申请新资源。
细粒度
应用程序被提交到集群之后,动态向集群管理器申请资源,只要等到资源满足一个任务的运行,便开始运行该任务,而不必等到所有资源全部到位。目前,基于Hadoop的MapReduce就是基于细粒度运行时环境构建方式。
Spark On Yarn
对于Spark on Yarn,目前仅支持粗粒度构建方式。不管何种方式,除了启动任务相关的组件外,每个Executor还需要启动一个RDD缓存管理服务 BlockManager,该服务采用了分布式Master/Slaves架构,其中,主控节点上启动Master服务BlockManagerMaster,它掌握了所有的RDD缓存未知,而从节点则启动Slave服务BlockManager,供客户端存取RDD使用。
深入源码
简单分析入口
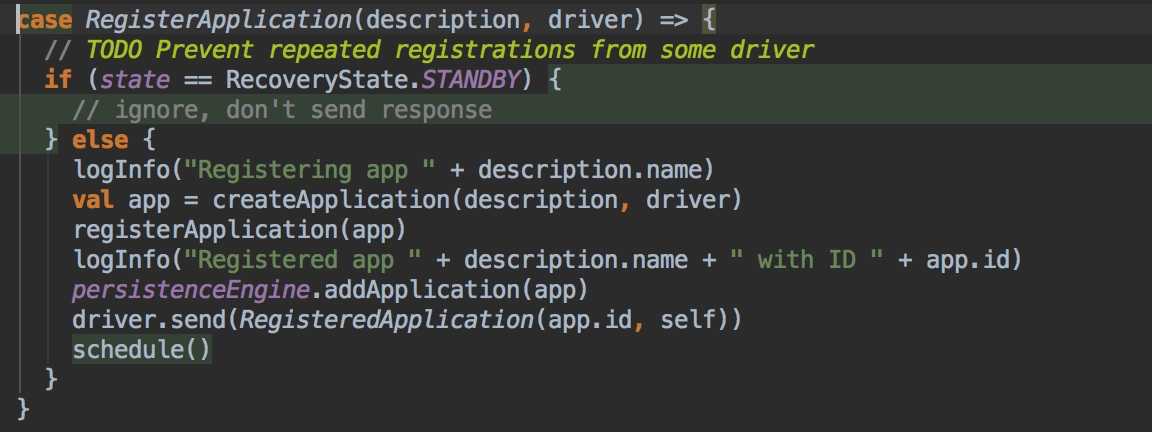
所有的 Application 启动都是先到 Master 去注册,那么咱们直接去 Master 中查看源码。 发现 Master extends ThreadSafeRpcEndpoint 而 ThreadSafeRpcEndpoint extends RpcEndpoint。 RpcEndpoint 的生命周期是 constructor -> onStart -> receive* -> onStop。所以咱们直接看 Master 的 receive 方法,然后找到了 registerAppliction 。
原创文章,转载请注明: 转载自LoserZhao – 诗和远方[ http://www.loserzhao.com/ ]
本文链接地址: http://www.loserzhao.com/bigdata/spark-schedule-source-analysis.html
文章的脚注信息由WordPress的wp-posturl插件自动生成
0 条评论。