1. 集群环境及安装包
1.1. 集群环境
主机名
IP
系统版本
部署服务
hadoop32
192.168.0.32
CentOS6.5_64
ES Node
hadoop33
192.168.0.33
CentOS6.5_6[……]
主机名
IP
系统版本
部署服务
hadoop32
192.168.0.32
CentOS6.5_64
ES Node
hadoop33
192.168.0.33
CentOS6.5_6[……]
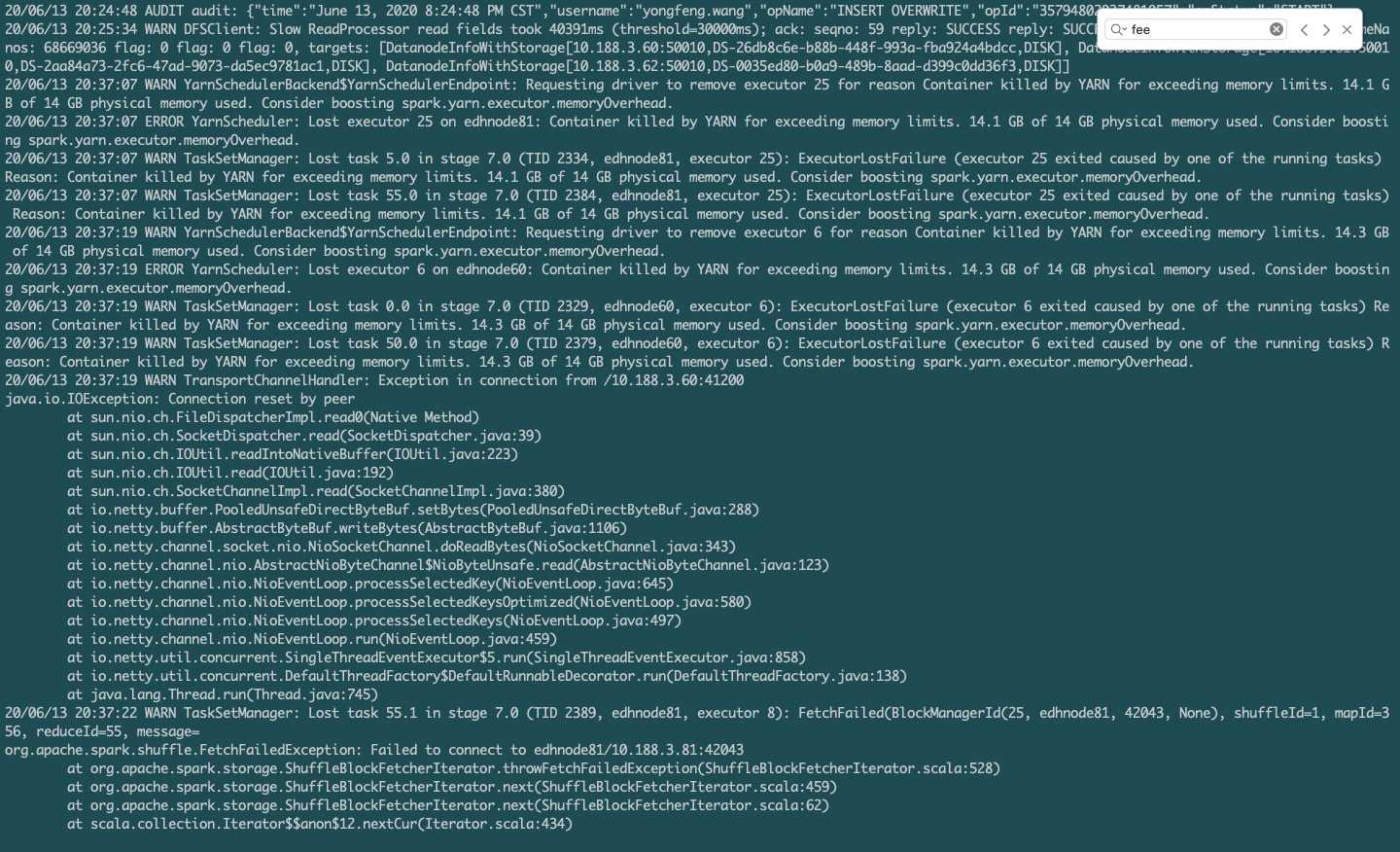
集群背景:48Core,256GMem,24台节点的集群。每台节点给Nodemanager分配了128G。
结果一次大型任务运行时,150亿的表和400亿的表做join时,每台节点的内存居然100%打满了。我这里的100%是整个节点的100%,而我们给所有大数据的组件内存才不到20[……]
[TOC]
注:UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
package cn.com.edata.udf; import org.apache.hadoop.hive.ql.exec.UDF; /** * @author zhaominmail@vip.qq.com * @Date 2016年5月9日 下午2:28:36 * @Describe */ public class HelloUDF extends UDF { public String evaluate(String str) { try { return "HelloWorld " + str; } catch (Exception e) { return null; } } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
package cn.com.edata.udf; import org.apache.hadoop.hive.ql.exec.NumericUDAF; import org.apache.hadoop.hive.ql.exec.UDAFEvaluator; import org.apache.hadoop.hive.serde2.io.DoubleWritable; /** * @author zhaominmail@vip.qq.com * @Date 2016年5月10日 下午6:26:15 * @Describe 自定义HiveUDAF * 1.需要import org.apache.hadoop.hive.ql.exec.UDAF以及org.apache.hadoop.hive.ql.exec.UDAFEvaluator,这两个包都是必须的 * 2.函数类需要继承UDAF类,内部类Evaluator实现UDAFEvaluator接口 * 3.Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数 */ public class SumUDAF extends NumericUDAF { public static class Evaluator implements UDAFEvaluator { private boolean mEmpty; private double mSum; public Evaluator() { super(); init(); } // 1)init函数类似于构造函数,用于UDAF的初始化 public void init() { mSum = 0; mEmpty = true; } // 2)iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean public boolean iterate(DoubleWritable o) { if (o != null) { mSum += o.get(); mEmpty = false; } return true; } // 3)terminatePartial无参数,其为iterate函数轮转结束后,返回乱转数据,iterate和terminatePartial类似于hadoop的Combiner public DoubleWritable terminatePartial() { return mEmpty ? null : new DoubleWritable(mSum); } // 4)merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean public boolean merge(DoubleWritable o) { if (o != null) { mSum += o.get(); mEmpty = false; } return true; } // 5)terminate返回最终的聚集函数结果 public DoubleWritable terminate() { return mEmpty ? null : new DoubleWritable(mSum); } } } |
一般数据存放在关系型数据库,Oracle、MySQL中。如果数据量不大,少于30G,量少于5000万条,可以用Sqoop 直接 Oracle -> HBase。
量大的话,HBase 性能会严重影响,建议
1、Sqoop Oracle -> HDFS;
2、HDFS -> HFi[……]
[TOC]
应用
版本
位数
备注
系统
CentOS 6.5
64
JDK
1.7.0_79
64
Maven
3.3.3
Hadoop
2.6.0
64[……]
我们要分析HDFS-NameNode的启动流程,就得从启动脚本开始一步步分析,当然开始之前,我们需要编译Hadoop的源码,具体的编译流程请参考我另外一篇博客 hadoop2.6.5源码编译。
我们启动Hadoop在2[……]
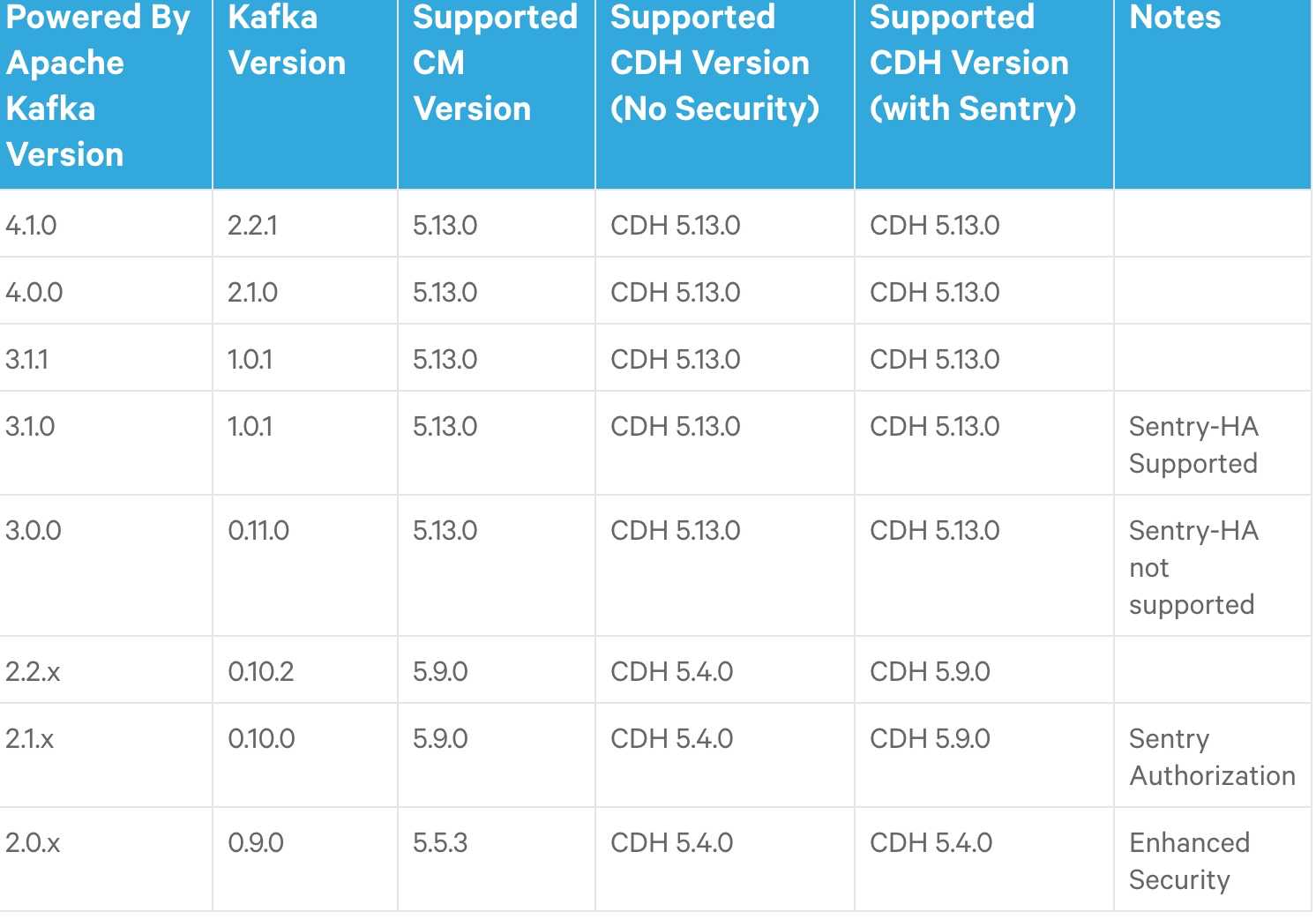
Kafka兼容性列表可以参考Cloudera的官方手册:
https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolid[……]
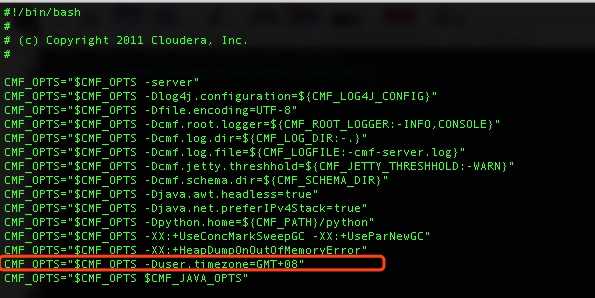
主机名
IP
系统版本
部署服务
hadoop32
192.168.0.32
CentOS6.5_64
CM Server、Agent、MySQL
hadoop33
192.168.0.33[……]
近期评论