1. 数据导入流程
一般数据存放在关系型数据库,Oracle、MySQL中。如果数据量不大,少于30G,量少于5000万条,可以用Sqoop 直接 Oracle -> HBase。
量大的话,HBase 性能会严重影响,建议
1、Sqoop Oracle -> HDFS;
2、HDFS -> HFi[……]
一般数据存放在关系型数据库,Oracle、MySQL中。如果数据量不大,少于30G,量少于5000万条,可以用Sqoop 直接 Oracle -> HBase。
量大的话,HBase 性能会严重影响,建议
1、Sqoop Oracle -> HDFS;
2、HDFS -> HFi[……]
[TOC]
应用
版本
位数
备注
系统
CentOS 6.5
64
JDK
1.7.0_79
64
Maven
3.3.3
Hadoop
2.6.0
64[……]
我们要分析HDFS-NameNode的启动流程,就得从启动脚本开始一步步分析,当然开始之前,我们需要编译Hadoop的源码,具体的编译流程请参考我另外一篇博客 hadoop2.6.5源码编译。
我们启动Hadoop在2[……]
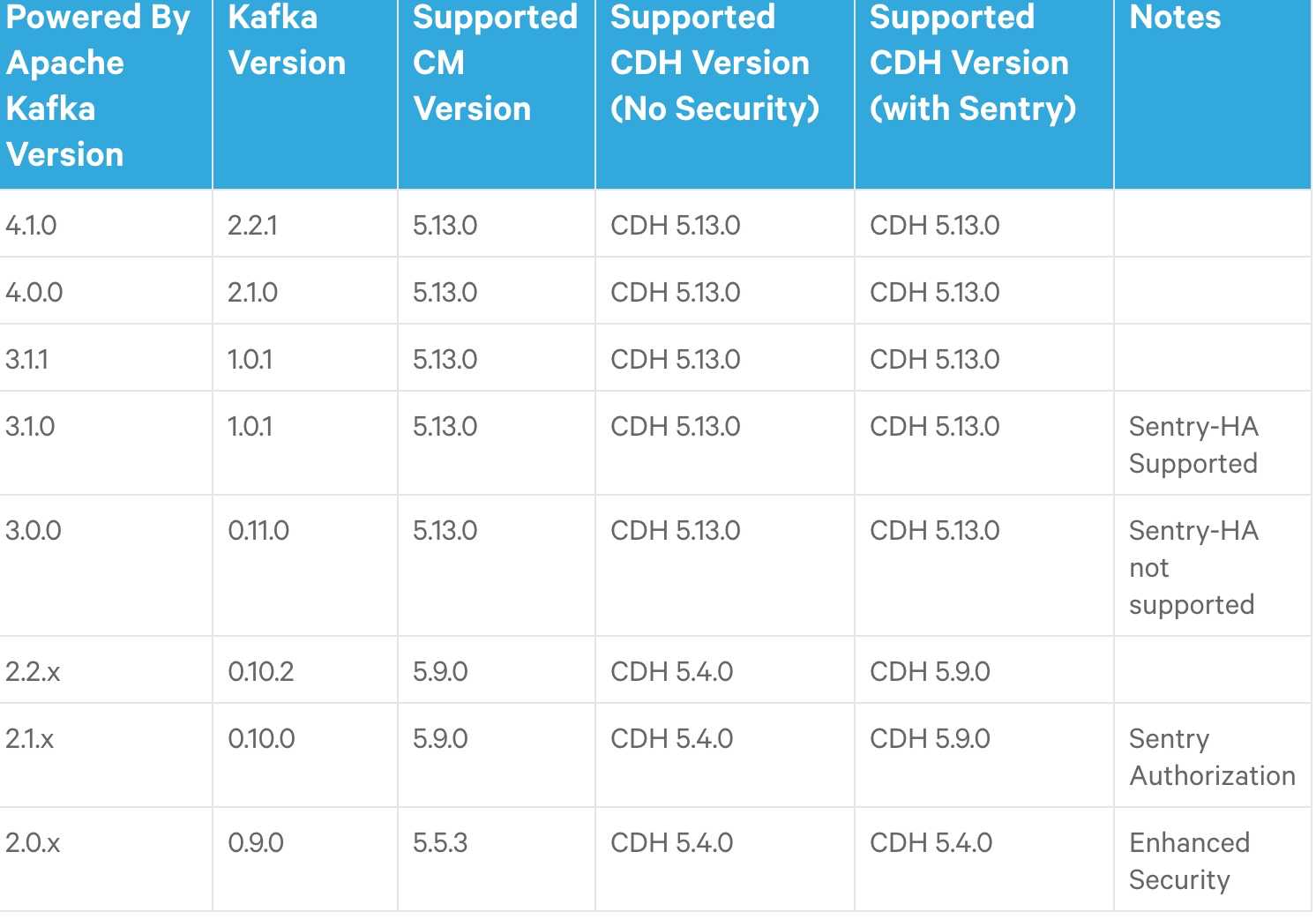
Kafka兼容性列表可以参考Cloudera的官方手册:
https://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolid[……]
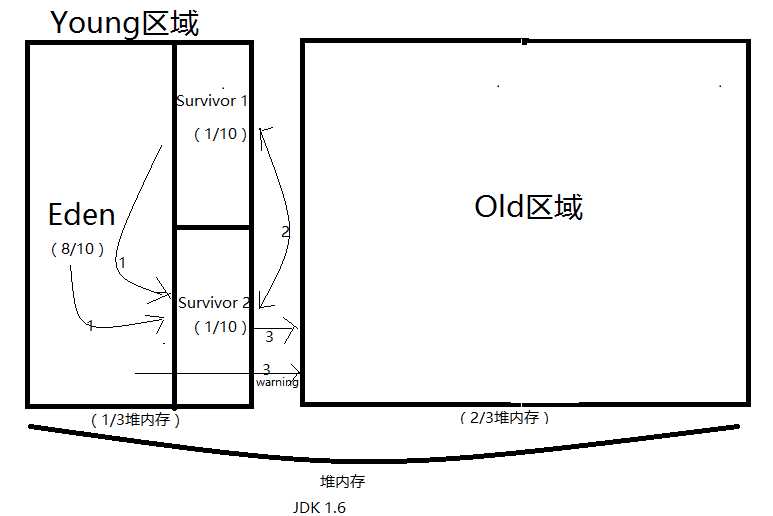
环境:JDK1.6
JAVA堆内存分为新生代(Young)和老年代(Old),比例为1:2。也就是如果有1.5G的堆内存,新生代内存为512M,老年代为1G。
而新生代又分为三块区域,Edent和Survivor 1和 Survivor 2。
Edent和Survivor 1和 S[......]
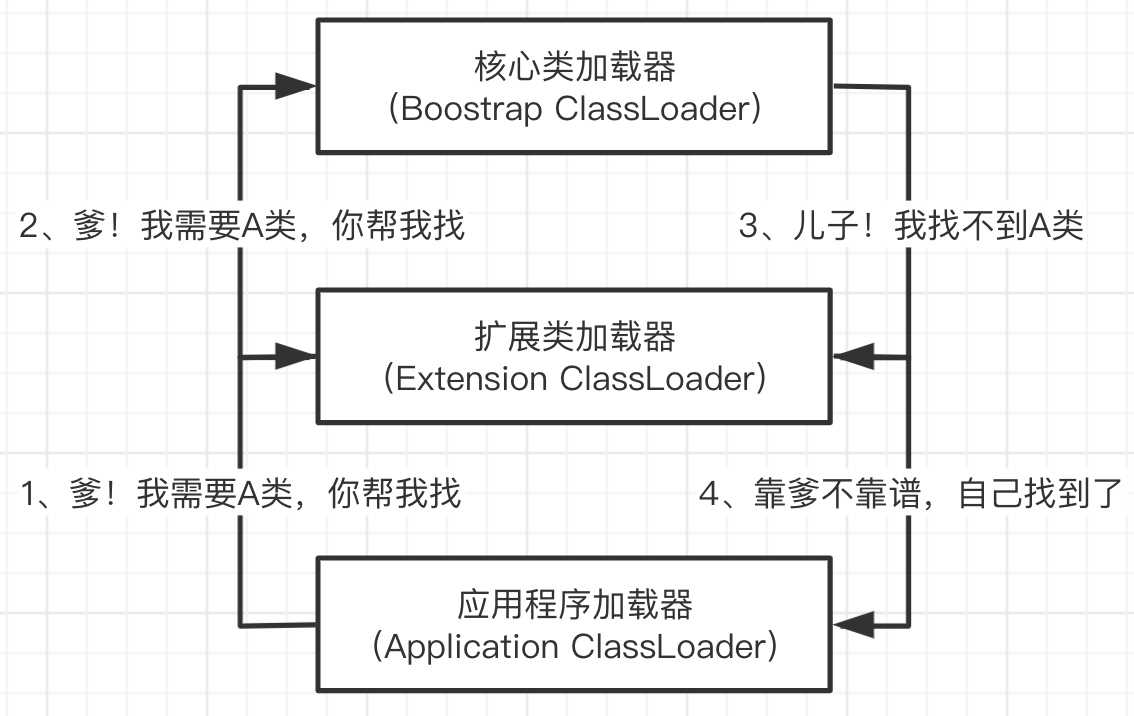
加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载
class文件中的 main 方法开始加载,用到哪些类,就加载哪些类。
执行 Student.class 中的 main方法
常用于年轻代的垃圾回收器,使用的算法为标记-清理。
单线程
常用于年轻代的垃圾回收器,使用的算法为标记-复制。
多线程
常用于老年代的垃圾回收器,使用的算法为标记-清理-整理。
CMS执行垃圾回收的过程:
1、初始标记;
2[……]
G1最大的特点是可以设置一个垃圾回收的预期停顿时间。
G1是直接把整个堆内存分为很多大小相当的 Region,默认是2048个。但是这些Region也有Eden、Survivor、Older区域概念。
|
作用
默认值[……]
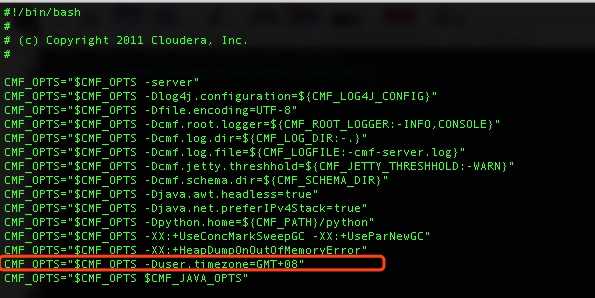
主机名
IP
系统版本
部署服务
hadoop32
192.168.0.32
CentOS6.5_64
CM Server、Agent、MySQL
hadoop33
192.168.0.33[……]
近期评论